import sys
sys.version'3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:41:22) [Clang 13.0.1 ]'import sys
sys.version'3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:41:22) [Clang 13.0.1 ]'import numpy as npnp.random.RandomState(2022);x = np.random.randn(200, 10)
w = np.random.randn(10)y = x @ w + np.random.randn(200)Create resamples using numpy.random
res = np.random.choice(range(200), 160, replace=False)
resarray([179, 149, 183, 158, 116, 7, 0, 72, 143, 67, 68, 184, 177,
38, 191, 125, 190, 76, 65, 150, 94, 12, 98, 123, 172, 132,
112, 168, 81, 110, 146, 64, 85, 74, 189, 104, 167, 144, 148,
135, 130, 46, 63, 181, 45, 1, 128, 103, 16, 30, 160, 176,
188, 107, 82, 41, 195, 35, 25, 152, 147, 11, 31, 139, 39,
118, 24, 23, 71, 17, 32, 197, 19, 44, 178, 180, 105, 62,
54, 91, 6, 117, 43, 18, 108, 155, 165, 134, 131, 142, 78,
61, 164, 26, 36, 55, 40, 97, 196, 169, 80, 187, 37, 88,
13, 59, 73, 79, 127, 75, 90, 14, 136, 113, 171, 174, 199,
47, 163, 57, 159, 95, 10, 49, 138, 198, 3, 102, 5, 122,
170, 182, 2, 141, 121, 115, 69, 53, 84, 93, 185, 194, 58,
34, 129, 126, 192, 66, 60, 106, 96, 156, 92, 166, 161, 56,
137, 101, 140, 21])res.size160We used replace=False in our call above to np.random.choice() to make sure we get unique training cases.
We can check it worked:
np.unique(res).size160x_train = x[res]
y_train = y[res]x_test = np.delete(x, res, axis = 0)
y_test = np.delete(y, res, axis = 0)x_train.shape, y_train.shape, x_test.shape, y_test.shape((160, 10), (160,), (40, 10), (40,))from sklearn import linear_model
mod = linear_model.LinearRegression().fit(x_train, y_train)mod.coef_array([ 0.92817805, 2.01373496, -1.28883035, 0.04119829, -1.10407096,
0.37597012, -1.21737787, 0.48829844, 0.80380437, -0.01914426])fitted = mod.predict(x_train)predicted = mod.predict(x_test)Using numpy to get mse:
np.mean(np.square(fitted - y_train))0.8358119945422942np.mean(np.square(predicted - y_test))0.8804826321233696Using sklearn’s metrics:
from sklearn.metrics import mean_squared_error
mean_squared_error(y_train, fitted)0.8358119945422942mean_squared_error(y_test, predicted)0.8804826321233696import matplotlib.pyplot as pltplt.scatter(y_train, fitted)<matplotlib.collections.PathCollection at 0x14f5b3ca0>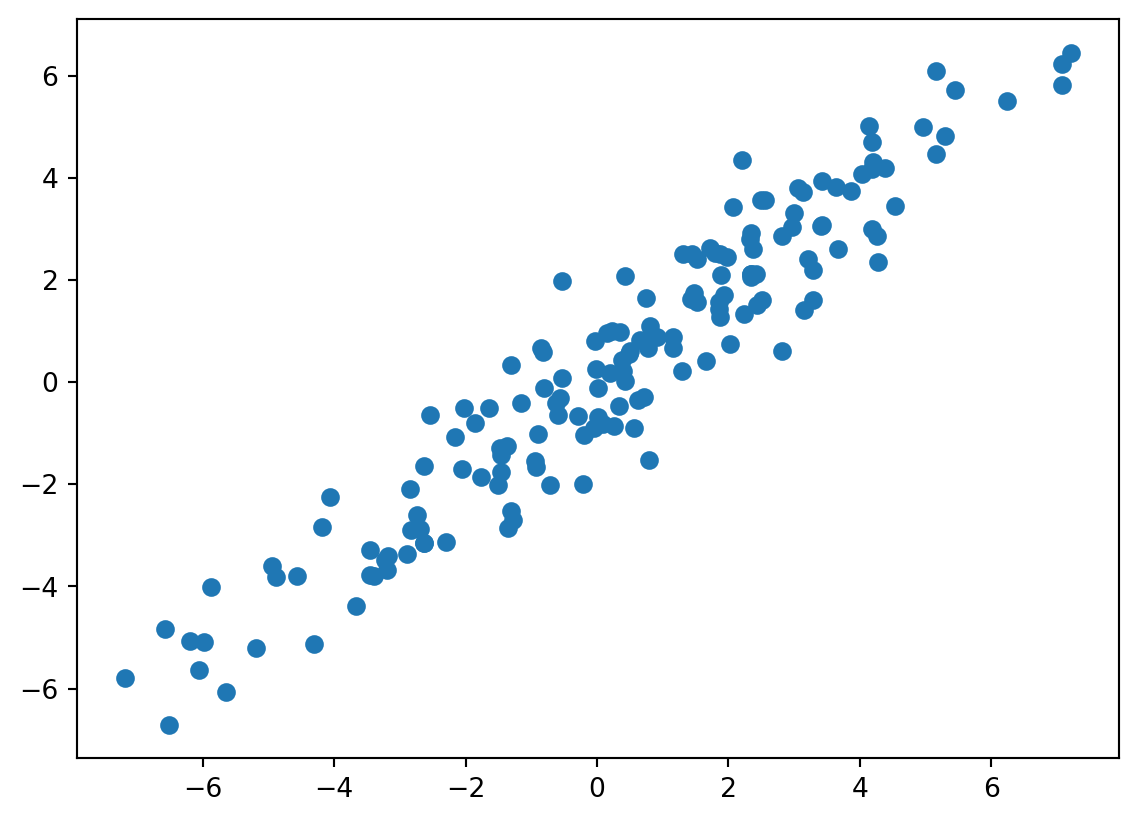
plt.scatter(y_test, predicted)<matplotlib.collections.PathCollection at 0x14fb01630>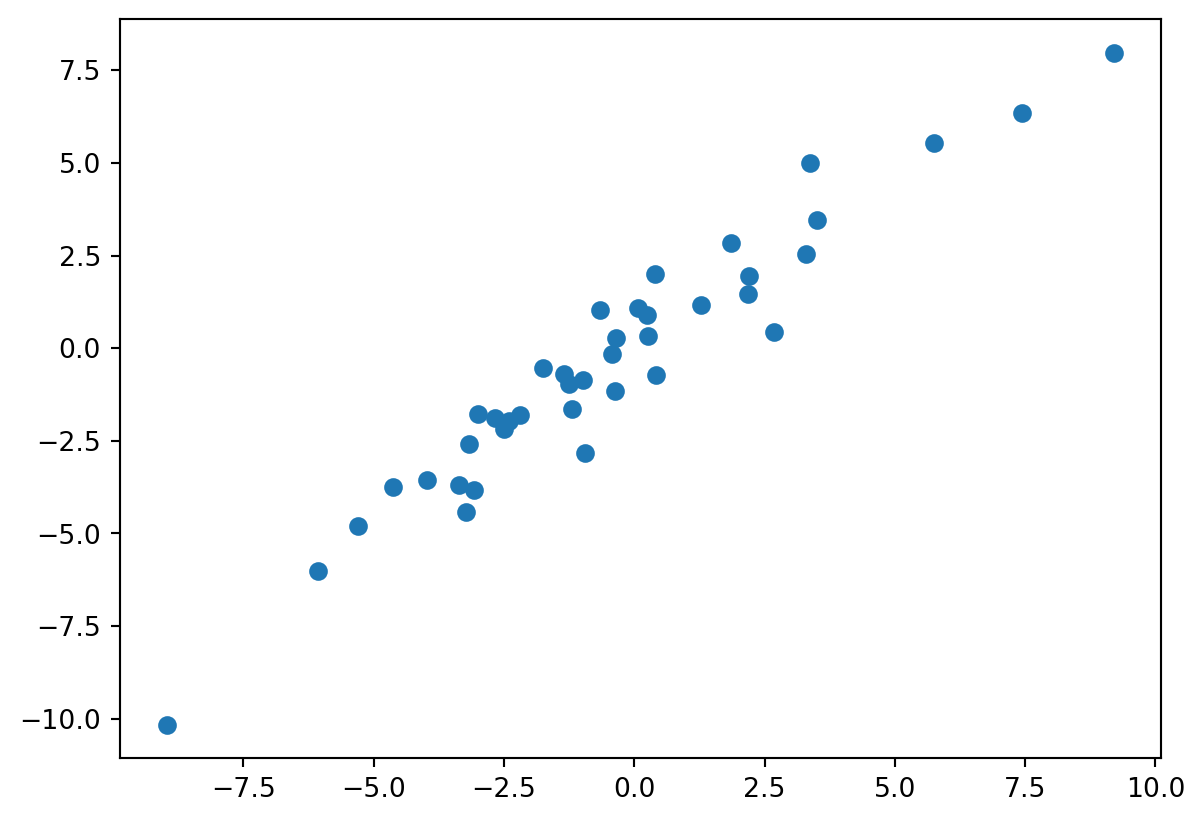
Example: 80% training, 20% testing split
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=2021)x_train.shape, y_train.shape, x_test.shape, y_test.shape((160, 10), (160,), (40, 10), (40,))from sklearn.model_selection import cross_val_scoremod = linear_model.LinearRegression()scores_5fold = cross_val_score(mod, x, y, cv=5)
scores_5foldarray([0.88940357, 0.88752802, 0.9354237 , 0.87075304, 0.93986659])The above defaults to scoring='r2', which report r-squared.
Note that if you want to output MSE, you must ask for negative mse - which sklearn uses so that is always maximizes the score:
scores_5fold = cross_val_score(mod,
x, y,
cv=5,
scoring='neg_mean_squared_error')
scores_5foldarray([-0.97539155, -0.99060429, -0.68414588, -1.16718933, -0.69287082])