x <- 15:24
x [1] 15 16 17 18 19 20 21 22 23 24An index is used to pick elements of a data structure (i.e. a vector, matrix, array, list, data frame, etc.). You can select, or exclude, one or multiple elements at a time. This means there are ways to index structures of any dimensionality, whether 1-, 2-, or N-dimensional. There are often multiple ways to index a given data structure (e.g. a 2-dimensional table or data frame).
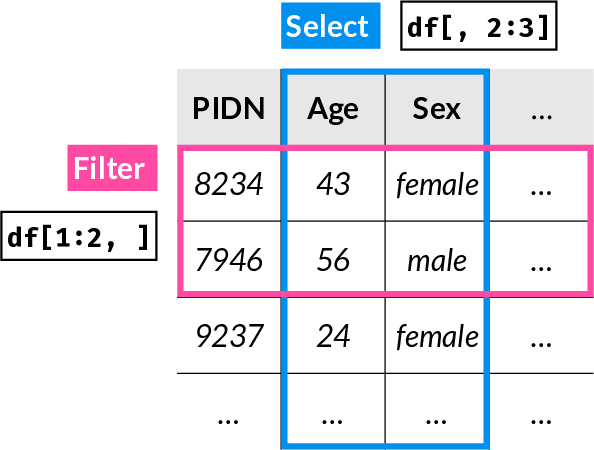
In data science, indexing 2-dimensional tables or data frames is one of the most common and important operations. The terms filter and select are often used:
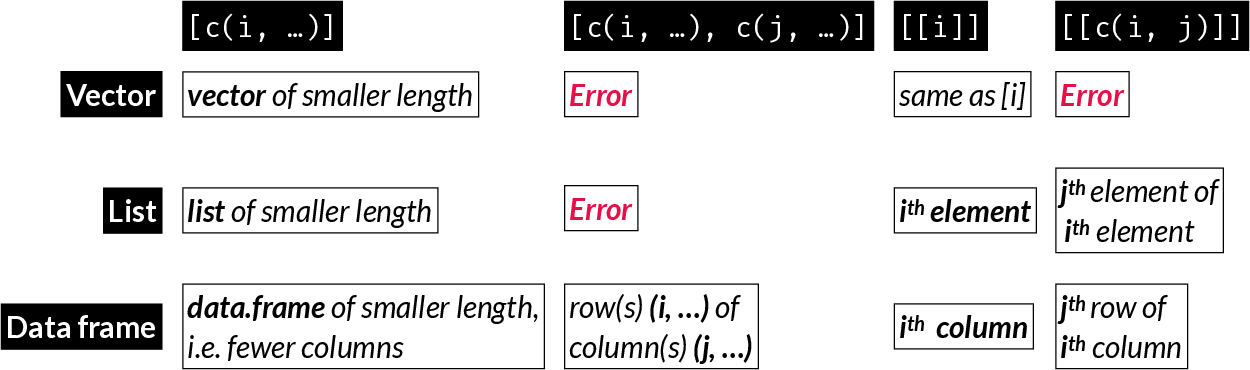
There are three types of index vectors you can use in R to identify elements of an object:
Integer indexing in R is 1-based, meaning the first item of a vector is in position 1. In contrast, many programming languages use 0-based indexing where the first element is in the 0th position, the second in the 1st, and the nth in the n-1 position.
To understand indexing, make sure you are very comfortable with the core R data structures: vectors, matrices, arrays, lists, and data.frames.
What is indexing used for?
Indexing can be used to get values from an object or to set values in an object.
The main indexing operator in R is the square bracket ([]).
As you’ll see below, lists use both single and double square brackets ([[]]).
Start with a simple vector:
x <- 15:24
x [1] 15 16 17 18 19 20 21 22 23 24Get the 5th element of a vector:
x[5][1] 19Get elements 6 through 9 of the same vector:
x[6:9][1] 20 21 22 23An integer index can be used to reverse order of elements:
x[5:3][1] 19 18 17Note that an integer index can be used to repeat elements. This is often done by accident, when someone passes the wrong vector as an index, so beware.
x[c(1, 1, 1, 4)][1] 15 15 15 18Logical indexes are usually created as the output of a logical operation, i.e. an elementwise comparison.
Select elements with value greater than 19:
idl <- x > 19The above comparison is vectorized (Chapter 17), meaning that the comparison is performed elementwise and the result is a logical vector of the same length as the original vector. In other words, x > 19 asks the question “is x[i] greater than 19” for each element i of x. The output of a logical operation is a logical vector, i.e. a vector that can only contain TRUE, FALSE, and NA values.
idl [1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUEYou can pass the logical vector as an index to the original vector to get the elements that correspond to TRUE in the logical vector:
x[idl][1] 20 21 22 23 24Logical vectors can be created directly in the brackets:
x[x > 19][1] 20 21 22 23 24x <- c(24, 32, 41, 37, 999, 999, 999)Indexing allows you to access specific elements, for example to perform calculations on them.
Get the mean of elements 1 through 4:
mean(x[1:4])[1] 33.5You can combine indexing with assignment to replace elements of an object.
Replace values in elements 1:4 with their log:
x[1:4] <- log(x[1:4])
x[1] 3.178054 3.465736 3.713572 3.610918 999.000000 999.000000 999.000000Replace elements that are equal to 999 with NA:
x[x == 999] <- NA
x[1] 3.178054 3.465736 3.713572 3.610918 NA NA NAReminder:
To index a 2D structure, whether a matrix or data frame, we use the form: [row, column].
The following indexing operations are therefore the same whether applied on a matrix or a data frame:
mat <- matrix(21:60, nrow = 10)
colnames(mat) <- paste0("Feature_", seq(ncol(mat)))
rownames(mat) <- paste0("Row_", seq(nrow(mat)))
mat Feature_1 Feature_2 Feature_3 Feature_4
Row_1 21 31 41 51
Row_2 22 32 42 52
Row_3 23 33 43 53
Row_4 24 34 44 54
Row_5 25 35 45 55
Row_6 26 36 46 56
Row_7 27 37 47 57
Row_8 28 38 48 58
Row_9 29 39 49 59
Row_10 30 40 50 60df <- as.data.frame(mat)
df Feature_1 Feature_2 Feature_3 Feature_4
Row_1 21 31 41 51
Row_2 22 32 42 52
Row_3 23 33 43 53
Row_4 24 34 44 54
Row_5 25 35 45 55
Row_6 26 36 46 56
Row_7 27 37 47 57
Row_8 28 38 48 58
Row_9 29 39 49 59
Row_10 30 40 50 60To get the contents of the fifth row, second column:
mat[5, 2][1] 35df[5, 2][1] 35We show the following on matrices, but they work just the same on data.frames.
If you want to select an entire row or an entire column, you leave the row or column index blank, but you must include a comma:
Get the first row:
mat[1, ]Feature_1 Feature_2 Feature_3 Feature_4
21 31 41 51 Get the second column:
mat[, 2] Row_1 Row_2 Row_3 Row_4 Row_5 Row_6 Row_7 Row_8 Row_9 Row_10
31 32 33 34 35 36 37 38 39 40 Note that colnames and rownames were added to the matrix above for convenience - if they are absent, there are no labels above each element.
You can define ranges for both rows and columns:
mat[6:7, 2:4] Feature_2 Feature_3 Feature_4
Row_6 36 46 56
Row_7 37 47 57You can use vectors to specify any combination of rows and columns.
Get rows 2, 4, and 7 of columns 1, 4, and 3:
Feature_1 Feature_4 Feature_3
Row_2 22 52 42
Row_4 24 54 44
Row_7 27 57 47Since a matrix is a vector with 2 dimensions, you can also index the underlying vector directly. Regardless of whether a matrix was created by row or by column (default), the data is stored and accessed by column. You can see that by converting the matrix to a one-dimensional vector:
as.vector(mat) [1] 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
[26] 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60same as:
c(mat) [1] 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
[26] 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60For example, ‘mat’ has 10 rows and 4 columns, therefore the 11th element is in row 1, column 2 - this only works with matrices, not data.frames:
mat[11][1] 31is the same as:
mat[1, 2][1] 31This is quite less commonly used, but potentially useful. It allows you to specify a series of individual [i, j] indexes, i.e. is a way to select multiple individual non-contiguous elements
An n-by-2 matrix can be used to index as a length n vector of [row, colum] indexes. Therefore, the above matrix, will return elements [2, 4], [4, 3], [7, 1]:
mat[idm][1] 52 44 27Identify rows with value greater than 36 on the second column:
The logical index for this operation is:
mat[, 2] > 36 Row_1 Row_2 Row_3 Row_4 Row_5 Row_6 Row_7 Row_8 Row_9 Row_10
FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE It can be used directly to index the matrix:
mat[mat[, 2] > 36, ] Feature_1 Feature_2 Feature_3 Feature_4
Row_7 27 37 47 57
Row_8 28 38 48 58
Row_9 29 39 49 59
Row_10 30 40 50 60Indexing a matrix or a data.frame can return either a smaller matrix/data.frame or a vector.
In general, many R functions return the simplest R object that can hold the output. As always, check function documentation to look for possible arguments that can change this and what the default behavior is. If you extract a column or a row, you get a vector:
Get the third column:
mat[, 3] Row_1 Row_2 Row_3 Row_4 Row_5 Row_6 Row_7 Row_8 Row_9 Row_10
41 42 43 44 45 46 47 48 49 50 class(mat[, 3])[1] "integer"You can specify drop = FALSE to stop R from dropping the unused dimension and return a matrix or data.frame of a single column:
mat[, 3, drop = FALSE] Feature_3
Row_1 41
Row_2 42
Row_3 43
Row_4 44
Row_5 45
Row_6 46
Row_7 47
Row_8 48
Row_9 49
Row_10 50df[, 3, drop = FALSE] Feature_3
Row_1 41
Row_2 42
Row_3 43
Row_4 44
Row_5 45
Row_6 46
Row_7 47
Row_8 48
Row_9 49
Row_10 50Check it is still a matrix or data.frame:
Reminder: A list can contain elements of different classes and of different lengths:
x <- list(one = 1001:1004,
two = sample(seq(0, 100, by = 0.1), size = 10),
three = c("Neuro", "Cardio", "Radio"),
four = median)
x$one
[1] 1001 1002 1003 1004
$two
[1] 77.1 59.8 12.6 9.7 38.0 64.7 97.6 8.5 92.7 68.0
$three
[1] "Neuro" "Cardio" "Radio"
$four
function (x, na.rm = FALSE, ...)
UseMethod("median")
<bytecode: 0x155fad6e0>
<environment: namespace:stats>You can access a single list element using:
[[ with either name or integer position
$ followed by name of the element (therefore only works if elements are named)For example, to access the third element:
x$three[1] "Neuro" "Cardio" "Radio" same as:
x[[3]][1] "Neuro" "Cardio" "Radio" same as:
x[["three"]][1] "Neuro" "Cardio" "Radio" To access a list element programmatically, i.e. using a name or integer index stored in a variable, only the bracket notation works. Therefore, programmatically, you would always use double brackets to access different elements:
idi <- 3
idc <- "three"
x[[idi]][1] "Neuro" "Cardio" "Radio" x[[idc]][1] "Neuro" "Cardio" "Radio" You can extract one or more list elements as a pruned list using single bracket [ notation. Similar to indexing of a vector, this can be either a logical, integer, or character vector:
x[3]$three
[1] "Neuro" "Cardio" "Radio" x["three"]$three
[1] "Neuro" "Cardio" "Radio" x[c(FALSE, FALSE, TRUE, FALSE)]$three
[1] "Neuro" "Cardio" "Radio" Get multiple elements:
x[2:3]$two
[1] 77.1 59.8 12.6 9.7 38.0 64.7 97.6 8.5 92.7 68.0
$three
[1] "Neuro" "Cardio" "Radio" # same as
x[c("two", "three")]$two
[1] 77.1 59.8 12.6 9.7 38.0 64.7 97.6 8.5 92.7 68.0
$three
[1] "Neuro" "Cardio" "Radio" # same as
x[c(FALSE, TRUE, TRUE, FALSE)]$two
[1] 77.1 59.8 12.6 9.7 38.0 64.7 97.6 8.5 92.7 68.0
$three
[1] "Neuro" "Cardio" "Radio" Given the following list:
We can access the 3rd element of the 2nd element:
x[[2]][3][1] "Radio"or
x[[c(2, 3)]][1] "Radio"This is called recursive indexing and is perhaps more often used by accident, when one instead wanted to extract the 2nd and 3rd elements:
x[c(2, 3)]$Dept
[1] "Neuro" "Cardio" "Radio"
$Age
[1] 57.29980 55.19141 57.13708 56.30935 57.28402 57.30505 58.38783 57.02346
[9] 58.17086 58.03640 59.72569 55.21018 57.46528 54.28655 57.88502 57.48371
[17] 54.83856 57.17818 56.09113 57.81507You can convert a list to a single vector containing all individual components of the original list using unlist(). Notice how names are automatically created based on the original structure:
x <- list(alpha = sample(seq(100), size = 10),
beta = sample(seq(100), size = 10),
gamma = sample(seq(100), size = 10))
x$alpha
[1] 61 64 88 57 49 74 98 59 79 18
$beta
[1] 85 13 94 43 58 48 2 15 14 32
$gamma
[1] 67 40 63 46 34 28 37 26 9 48unlist(x) alpha1 alpha2 alpha3 alpha4 alpha5 alpha6 alpha7 alpha8 alpha9 alpha10
61 64 88 57 49 74 98 59 79 18
beta1 beta2 beta3 beta4 beta5 beta6 beta7 beta8 beta9 beta10
85 13 94 43 58 48 2 15 14 32
gamma1 gamma2 gamma3 gamma4 gamma5 gamma6 gamma7 gamma8 gamma9 gamma10
67 40 63 46 34 28 37 26 9 48 If you want to drop the names, you can set the use.names argument to FALSE or wrap the above in unname():
In data science and related fields the terms filter and select are commonly used:
We’ve saw above that a data frame can be indexed in many ways similar to a matrix, i.e. by defining rows and columns. At the same time, we know that a data frame is a rectangular list. Like a list, its elements are vectors of any type (integer, double, character, factor, and more) but, unlike a list, they have to be of the same length. A data frame can also be indexed the same way as a list and similar to list indexing, notice that some methods return a smaller data frame, while others return vectors.
You can index a data frame using all the ways you can index a list and all the ways you can index a matrix.
Let’s create a simple data frame:
x <- data.frame(Feat_1 = 21:25,
Feat_2 = rnorm(5),
Feat_3 = paste0("rnd_", sample(seq(100), size = 5)))
x Feat_1 Feat_2 Feat_3
1 21 1.11232356 rnd_3
2 22 0.06007728 rnd_45
3 23 -0.06447830 rnd_16
4 24 0.46506291 rnd_82
5 25 -0.50433435 rnd_10Just like in a list, using double brackets [[ or the $ operator returns an element, i.e. a vector:
x$Feat_2[1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435x[[2]][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435x[, 2][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435Accessing a column by name using square brackets, returns a single-column data.frame:
x["Feat_2"] Feat_2
1 1.11232356
2 0.06007728
3 -0.06447830
4 0.46506291
5 -0.50433435Accessing a column by [row, column] either by position or name, returns a vector by default:
x[, 2][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435x[, "Feat_2"][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435As we saw earlier, we can specify drop = FALSE to return a data.frame:
As in lists, all indexing and slicing operations, with the exception of the $ notation, work with a variable holding either a column name of or an integer location:
idi <- 2
idc <- "Feat_2"
x[idi] Feat_2
1 1.11232356
2 0.06007728
3 -0.06447830
4 0.46506291
5 -0.50433435x[idc] Feat_2
1 1.11232356
2 0.06007728
3 -0.06447830
4 0.46506291
5 -0.50433435x[[idi]][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435x[[idc]][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435x[, idi][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435x[, idc][1] 1.11232356 0.06007728 -0.06447830 0.46506291 -0.50433435x[, idi, drop = FALSE] Feat_2
1 1.11232356
2 0.06007728
3 -0.06447830
4 0.46506291
5 -0.50433435x[, idc, drop = FALSE] Feat_2
1 1.11232356
2 0.06007728
3 -0.06447830
4 0.46506291
5 -0.50433435Extracting multiple columns returns a data frame:
x[, 2:3] Feat_2 Feat_3
1 1.11232356 rnd_3
2 0.06007728 rnd_45
3 -0.06447830 rnd_16
4 0.46506291 rnd_82
5 -0.50433435 rnd_10class(x[, 2:3])[1] "data.frame"Unlike indexing a row of a matrix, indexing a row of a data.frame returns a single-row data.frame, since it contains multiple columns of potentially different types:
Convert into a list using c():
Convert into a (named) vector using unlist():
x[x$Feat_1 > 22, ] Feat_1 Feat_2 Feat_3
3 23 -0.0644783 rnd_16
4 24 0.4650629 rnd_82
5 25 -0.5043344 rnd_10In this chapter, we have learned how to use both integer and logical indexes.
A logical index needs to be of the same dimensions as the object it is indexing (unless you really want to recycle values - see chapter on vectorization):
you are specifying whether to include or exclude each element
An integer index will be shorter than the object it is indexing: you are specifying which subset of elements to include (or with a - in front, which elements to exclude)
It’s easy to convert between the two types.
For example, start with a sequence of integers:
x <- 21:30
x [1] 21 22 23 24 25 26 27 28 29 30Let’s create a logical index based on two inequalities:
logical_index <- x > 23 & x < 28
logical_index [1] FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSEwhich():The common mistake is to attempt to convert a logical index to an integer index using as.integer(). This results in a vector of 1’s and 0’s, NOT an integer index.which() converts a logical index to an integer index.
which() literally gives the position of all TRUE elements in a vector, thus converting a logical to an integer index:
integer_index <- which(logical_index)
integer_index[1] 4 5 6 7i.e. positions 4, 5, 6, 7 of the logical_index are TRUE
A logical and an integer index are equivalent if they select the exact same elements
Let’s check than when used to index x, they both return the same result:
x[logical_index][1] 24 25 26 27x[integer_index][1] 24 25 26 27all(x[logical_index] == x[integer_index])[1] TRUEOn the other hand, if we want to convert an integer index to a logical index, we can begin with a logical vector of the same length or dimension as the object we want to index with all FALSE values:
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSEAnd use the integer index to replace the corresponding elements to TRUE:
logical_index_too[integer_index] <- TRUE
logical_index_too [1] FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSEThis, of course, is the same as the logical index we started with.
all(logical_index == logical_index_too)[1] TRUEVery often, we want to use an index, whether logical or integer, to exclude cases instead of to select cases. To do that with a logical integer, we simply use an exclamation point in front of the index to negate each element (convert each TRUE to FALSE and each FALSE to TRUE):
logical_index [1] FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSE!logical_index [1] TRUE TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUEx[!logical_index][1] 21 22 23 28 29 30To exclude elements using an integer index, R allows you to use negative indexing:
x[-integer_index][1] 21 22 23 28 29 30To get the complement of an index, you negate a logical index (!logical_index) or you subtract an integer index (-integer_index).
NAs when indexingAssume a simple data.frame with a missing value in the Age column:
df <- data.frame(
Age = c(24, 29, 36, NA, 45, 56, 75),
SBP = rnorm(7, mean = 120, sd = 10)
)Create a logical index to select all cases older than 32:
idl <- df[["Age"]] > 32
idl[1] FALSE FALSE TRUE NA TRUE TRUE TRUEApply the index on the SBP column:
df[["SBP"]][idl][1] 129.6031 NA 104.3068 112.9225 109.6982Similarly, an integer index containing NA, will return NA for the corresponding element:
df[["SBP"]][c(3, 4, NA, 5)][1] 129.6031 126.3796 NA 104.3068But which() treats NA as FALSE:
idi <- which(df[["Age"]] > 32)
idi[1] 3 5 6 7df[["SBP"]][idi][1] 129.6031 104.3068 112.9225 109.6982For example, to filter the iris dataset to only include rows where the Species column is setosa, we can use the following code:
Your turn: Complete the following code to filter the iris dataset so that it only includes rows where Sepal.Length is greater than 7.5.
Now, run the following block to check your answer:
Solution:
iris_f <- iris[iris$Sepal.Length > 7.5, ]In base R, you can filter any tabular dataset (e.g. data.frame or matrix) using square bracket indexing. The syntax is data[condition, ], where condition is a logical vector that specifies which rows to keep. In this case, we filtered the iris dataset to only include rows where the Sepal.Length column is greater than 7.5.
For more information, see ?Extract.