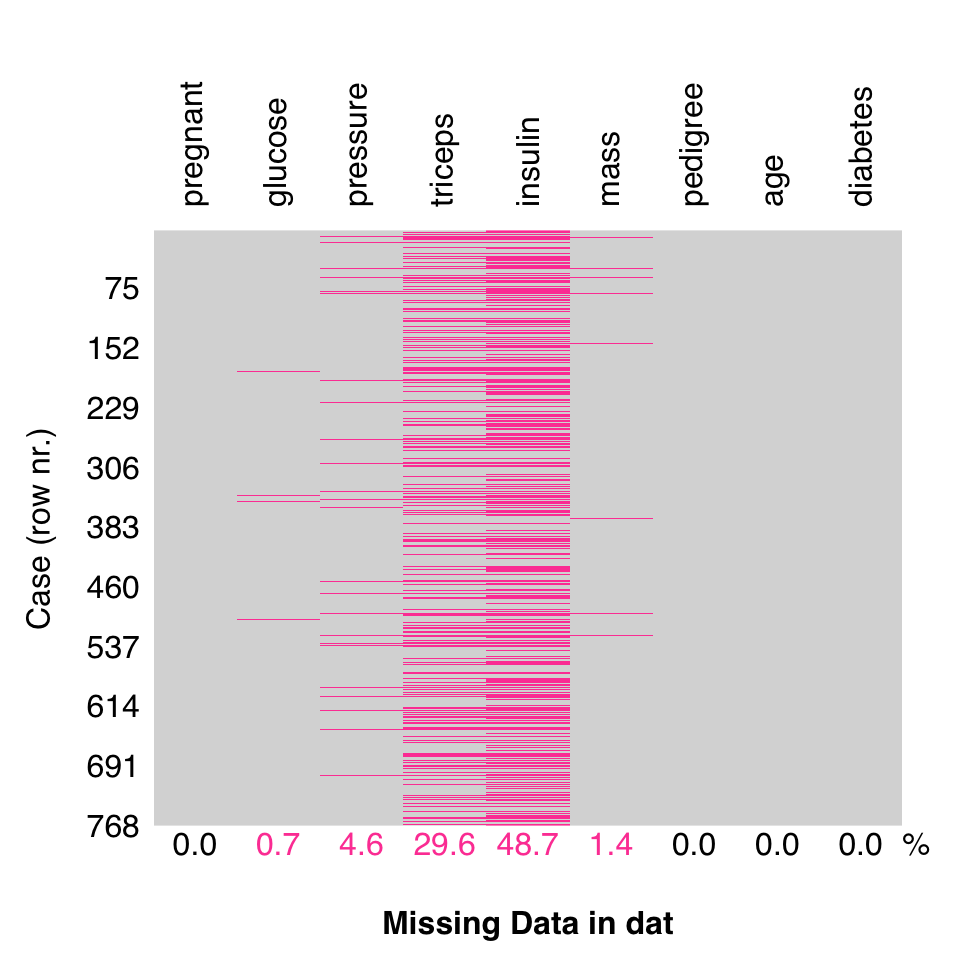
Missing data is a very common issue in statistics and data science.
Data may be missing for a variety of reasons. We often characterize the type of missingness using the following three types (Mack, Su, and Westreich 2018):
Missing completely at random (MCAR): “The fact that the data are missing is independent of the observed and unobserved data”
Missing at random (MAR): “The fact that the data are missing is systematically related to the observed but not the unobserved data”
Missing not at random (MNAR): “The fact that the data are missing is systematically related to the unobserved data”
29.1 Check for missing data
You can use your favorite base R commands to check for missing data, count NA elements by row, by column, total, etc.
Let’s load the PimaIndiansDiabetes2 dataset from the mlbench package and make a copy of it to variable dat. Remember to check the class of a new object you didn’t create yourself with class(), check its dimensions, if applicable, with dim(), and a get a summary of its structure including data types with str():
The above suggests there is one or more NA values in the dataset.
We can create a logical index of NA values using is.na(). Remember that the output of is.na() is a logical matrix with the same dimensions as the dataset:
One way to count missing values is with sum(is.na()). Remember that a logical array is coerced to an integer array for mathematical operations, where TRUE becomes 1 and FALSE becomes 0. Therefore, calling sum() on a logical index counts the number of TRUE elements (and since we are applying it on the index of NA values, it counts the number of elements with missing values):
dat: A data.table with 768 rows and 9 columns
Data types
* 8 numeric features
* 0 integer features
* 1 factor, which is not ordered
* 0 character features
* 0 date features
Issues
* 0 constant features
* 0 duplicate cases
* 5 features include 'NA' values; 652 'NA' values total
* 5 numeric
Recommendations * Consider imputing missing values or use complete cases only
29.2 Handle missing data
Different approaches can be used to handle missing data:
Do nothing - if your algorithm(s) can handle missing data (decision trees!)
Exclude data: Use complete cases only
Fill in (make up) data: Replace or Impute
Replace with median/mean
Predict missing from present
Single imputation
Multiple imputation
29.2.1 Do nothing
Algorithms like decision trees and ensemble methods that use decision trees like random forest and gradient boosting can handle missing data, depending on the particular implementation. For example, rpart::rpart() which is used by rtemis::s_CART() has no trouble with missing data in the predictors:
09-28-23 21:48:19 Hello, egenn [s_CART]
09-28-23 21:48:19 Imbalanced classes: using Inverse Frequency Weighting [dataPrepare]
.:Classification Input Summary
Training features: 768 x 8
Training outcome: 768 x 1
Testing features: Not available
Testing outcome: Not available
09-28-23 21:48:20 Training CART... [s_CART]
.:CART Classification Training Summary Reference Estimatedneg pos neg 426 89
pos 74 179
Overall
Sensitivity 0.8520
Specificity 0.6679
Balanced Accuracy 0.7600
PPV 0.8272
NPV 0.7075
F1 0.8394
Accuracy 0.7878
AUC 0.7854
Positive Class: neg09-28-23 21:48:20 Completed in 0.01 minutes (Real: 0.43; User: 0.41; System: 0.02) [s_CART]
29.2.2 Use complete cases only
R’s builtin complete.cases() function returns, as the name suggests, a logical index of cases (i.e. rows) that have no missing values, i.e. are complete.
We lost 376 cases in the above example. That’s quite a few, so, for this dataset, we probably want to look at options that do not exclude cases.
29.2.3 Replace with a fixed value
We can manually replace missing values with the mean or median in the case of a continuous variable, or with the mode in the case of a categorical feature.
For example, to replace the first feature’s missing values with the mean:
dat_pre: A data.table with 768 rows and 9 columns
Data types
* 8 numeric features
* 0 integer features
* 1 factor, which is not ordered
* 0 character features
* 0 date features
Issues
* 0 constant features
* 0 duplicate cases
* 0 missing values
Recommendations * Everything looks good
You may want to include a “missingness” column that indicates which cases were imputed to include in your model. You can create this simply by running:
09-28-23 21:48:20 Preprocessing dat... [preprocess]
09-28-23 21:48:20 Created missingness indicator for glucose... [preprocess]
09-28-23 21:48:20 Created missingness indicator for pressure... [preprocess]
09-28-23 21:48:20 Created missingness indicator for triceps... [preprocess]
09-28-23 21:48:20 Created missingness indicator for insulin... [preprocess]
09-28-23 21:48:20 Created missingness indicator for mass... [preprocess]
09-28-23 21:48:20 Imputing missing values using mean and get_mode... [preprocess]
09-28-23 21:48:20 Completed in 5e-05 minutes (Real: 3e-03; User: 3e-03; System: 0.00) [preprocess]
One option to handle missing data in categorical variables, is to introduce a new level of “missing” to the factor, instead of replacing with the mode, for example. If we bin a continuous variable to convert to categorical, the same can then also be applied.
Since no factors have missing values in the current dataset we create a copy and replace some data with NA:
In longitudinal / timeseries data, we may want to replace missing values with the last observed value. This is called last observation carried forward (LOCF). As always, whether this procedure is appropriate depend the reasons for missingness. The zoo and DescTools packages provide commands to perform LOCF.
Some simulated data. We are missing blood pressure measurements on Saturdays and Sundays:
dat<-data.frame( Day =rep(c("Mon", "Tues", "Wed", "Thu", "Fri", "Sat", "Sun"), times =3), SBP =sample(105:125, size =7*3, replace =TRUE))dat$SBP[dat$Day=="Sat"|dat$Day=="Sun"]<-NAdat
Day SBP
1 Mon 123
2 Tues 124
3 Wed 116
4 Thu 125
5 Fri 118
6 Sat NA
7 Sun NA
8 Mon 121
9 Tues 117
10 Wed 109
11 Thu 121
12 Fri 121
13 Sat NA
14 Sun NA
15 Mon 116
16 Tues 111
17 Wed 110
18 Thu 118
19 Fri 110
20 Sat NA
21 Sun NA
dat_rfimp: A data.table with 150 rows and 5 columns
Data types
* 4 numeric features
* 0 integer features
* 1 factor, which is not ordered
* 0 character features
* 0 date features
Issues
* 0 constant features
* 1 duplicate case
* 0 missing values
Recommendations * Consider removing the duplicate case
Note: The default method for preprocess(impute = TRUE) is to use missRanger.
29.2.5.2 Multiple imputation
Multiple imputation creates multiple estimates of the missing data. It is more statistically valid for small datasets, especially when the goal is to get accurate estimates of a summary statistics, but may not be practical for larger datasets. It is not usually considered an option for machine learning (where duplicating cases may add bias and complexity in resampling). The package mice is a popular choice for multiple imputation in R.
Buuren, S van, and Karin Groothuis-Oudshoorn. 2010. “Mice: Multivariate Imputation by Chained Equations in r.”Journal of Statistical Software, 1–68.
Mack, Christina, Zhaohui Su, and Daniel Westreich. 2018. “Managing Missing Data in Patient Registries: Addendum to Registries for Evaluating Patient Outcomes: A User’s Guide, [Internet].”
Stekhoven, Daniel J, and Peter Bühlmann. 2012. “MissForest—Non-Parametric Missing Value Imputation for Mixed-Type Data.”Bioinformatics 28 (1): 112–18.
Wright, Marvin N, and Andreas Ziegler. 2015. “Ranger: A Fast Implementation of Random Forests for High Dimensional Data in c++ and r.”arXiv Preprint arXiv:1508.04409.