library(rtemis) .:rtemis 0.97.4 🌊 aarch64-apple-darwin20We cannot know ahead of time which model will perform best in a given dataset. This is often referred to as the “no free lunch theorem” (Wolpert 1996). For this reason, we often train a suite of ML algorithms and compare model performance. In contexts where maximum performance is required, a common practice involves taking the outputs of multiple predictive models and using them as input to another model. This is called stacking or blending. In rtemis, this is referred to as a meta-model, a more general term for a model trained on the predictions of other models not necessarilly trained on the same data. This practice is very popular in competitions (like Kaggle) where the final test set is not available to the model trainer and even a tiny performance boost can mean a better position in the leaderboard.
Below is a simple example of how to use meta_mod() to train two base learners and combine their predictions in a meta-model. Any rtemis algorithm can be used for the base learners or the meta learner.
library(rtemis) .:rtemis 0.97.4 🌊 aarch64-apple-darwin20x <- rnormmat(500, 80, seed = 2021)
y <- x[, 3] + x[, 5] + x[, 7]^2 + x[, 9]*x[, 11]
dat <- data.frame(x, y)
res <- resample(dat)06-30-24 10:57:43 Input contains more than one columns; will stratify on last [resample]
.:Resampling Parameters
n.resamples: 10
resampler: strat.sub
stratify.var: y
train.p: 0.75
strat.n.bins: 4
06-30-24 10:57:43 Created 10 stratified subsamples [resample]
dat_train <- dat[res$Subsample_1, ]
dat_test <- dat[-res$Subsample_1, ]mod_glm <- s_GLM(dat_train, dat_test)06-30-24 10:57:43 Hello, egenn [s_GLM]
.:Regression Input Summary
Training features: 373 x 80
Training outcome: 373 x 1
Testing features: 127 x 80
Testing outcome: 127 x 1
06-30-24 10:57:43 Training GLM... [s_GLM]
.:GLM Regression Training Summary
MSE = 2.03 (59.17%)
RMSE = 1.43 (36.10%)
MAE = 1.09 (37.55%)
r = 0.77 (p = 3.7e-74)
R sq = 0.59
.:GLM Regression Testing Summary
MSE = 3.93 (30.38%)
RMSE = 1.98 (16.56%)
MAE = 1.47 (20.95%)
r = 0.58 (p = 1.1e-12)
R sq = 0.30
06-30-24 10:57:43 Completed in 4.8e-04 minutes (Real: 0.03; User: 0.03; System: 2e-03) [s_GLM]
mod_cart <- s_CART(dat_train, dat_test,
maxdepth = 20,
prune.cp = c(.01, .05, .1))06-30-24 10:57:43 Hello, egenn [s_CART]
.:Regression Input Summary
Training features: 373 x 80
Training outcome: 373 x 1
Testing features: 127 x 80
Testing outcome: 127 x 1
06-30-24 10:57:43 Running grid search... [gridSearchLearn]
.:Resampling Parameters
n.resamples: 5
resampler: kfold
stratify.var: y
strat.n.bins: 4
06-30-24 10:57:43 Created 5 independent folds [resample]
.:Search parameters
grid.params:
maxdepth: 20
minsplit: 2
minbucket: 1
cp: 0.01
prune.cp: 0.01, 0.05, 0.1
fixed.params:
method: anova
model: TRUE
maxcompete: 0
maxsurrogate: 0
usesurrogate: 2
surrogatestyle: 0
xval: 0
cost: 1, 1, 1, 1, 1, 1...
ifw: TRUE
ifw.type: 2
upsample: FALSE
downsample: FALSE
resample.seed: NULL
06-30-24 10:57:43 Tuning Classification and Regression Trees by exhaustive grid search. [gridSearchLearn]
06-30-24 10:57:43 5 inner resamples; 15 models total; running on 8 workers (aarch64-apple-darwin20) [gridSearchLearn]
.:Best parameters to minimize MSE
best.tune:
maxdepth: 20
minsplit: 2
minbucket: 1
cp: 0.01
prune.cp: 0.01
06-30-24 10:57:43 Completed in 4.2e-03 minutes (Real: 0.25; User: 0.08; System: 0.09) [gridSearchLearn]
06-30-24 10:57:43 Training CART... [s_CART]
.:CART Regression Training Summary
MSE = 1.22 (75.42%)
RMSE = 1.11 (50.42%)
MAE = 0.86 (50.80%)
r = 0.87 (p = 4.4e-115)
R sq = 0.75
.:CART Regression Testing Summary
MSE = 2.87 (49.05%)
RMSE = 1.70 (28.62%)
MAE = 1.18 (36.84%)
r = 0.74 (p = 3.3e-23)
R sq = 0.49
06-30-24 10:57:43 Completed in 4.6e-03 minutes (Real: 0.28; User: 0.11; System: 0.09) [s_CART]
mod_meta <- meta_mod(dat_train, dat_test,
base.mods = c("glm", "cart"),
base.params = list(glm = list(),
cart = list(maxdepth = 20,
prune.cp = c(.01, .05, .1))),
meta.mod = "glm")06-30-24 10:57:43 Hello, egenn [meta_mod]
.:Regression Input Summary
Training features: 373 x 80
Training outcome: 373 x 1
Testing features: 127 x 80
Testing outcome: 127 x 1
.:Resampling Parameters
n.resamples: 4
resampler: kfold
stratify.var: y
strat.n.bins: 4
06-30-24 10:57:43 Created 4 independent folds [resample]
I will train 2 base learners: GLM, CART using 4 internal resamples (kfold), and build a GLM meta model Training 2 base learners on 4 training set resamples (8 models total)...
06-30-24 10:57:44 Training GLM meta learner... [meta_mod]
06-30-24 10:57:44 Hello, egenn [s_GLM]
.:Regression Input Summary
Training features: 373 x 2
Training outcome: 373 x 1
Testing features: Not available
Testing outcome: Not available
06-30-24 10:57:44 Training GLM... [s_GLM]
.:GLM Regression Training Summary
MSE = 2.90 (41.82%)
RMSE = 1.70 (23.72%)
MAE = 1.26 (27.75%)
r = 0.65 (p = 1.5e-45)
R sq = 0.42
06-30-24 10:57:44 Completed in 1.5e-04 minutes (Real: 0.01; User: 0.01; System: 2e-03) [s_GLM]
06-30-24 10:57:44 Training 2 base learners on full training set... [meta_mod]
.:META.GLM.CART Regression Training Summary
MSE = 1.17 (76.42%)
RMSE = 1.08 (51.44%)
MAE = 0.80 (53.95%)
r = 0.89 (p = 1.1e-126)
R sq = 0.76
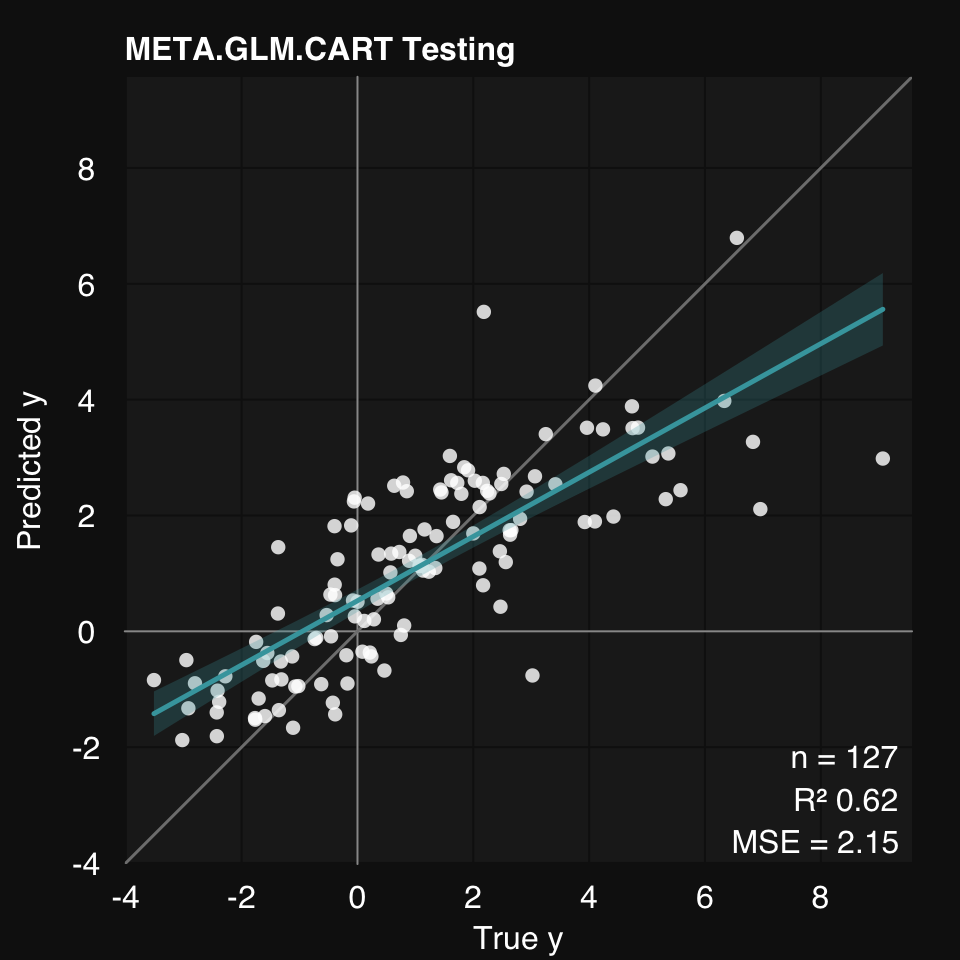
.:META.GLM.CART Regression Testing Summary
MSE = 2.15 (61.95%)
RMSE = 1.46 (38.32%)
MAE = 1.07 (42.79%)
r = 0.79 (p = 1.1e-28)
R sq = 0.62
06-30-24 10:57:45 Completed in 0.02 minutes (Real: 1.37; User: 0.50; System: 0.39) [meta_mod]